TL;DR
- Фронтопс — перенос девопс практик на фронтенд, так как у фронтенда есть своя специфика.
- Основная проблема — многие фронтендеры привыкли работать с хорошими инструментами, не зная, как они работают внутри, не понимая, что происходит с кодом после того, как он написан.
- Каждому фронтендеру нужно понимать, как собирается его проект, что происходит после сборки, как и в каком виде код доходит до пользователя, иметь представление об используемых и существующих инструментах
Предыдущие два года на более, чем двух проектах я занимался такой деятельностью, которую обычно называют «FrontOps». Давайте разберемся, какие у фронтопса проблемы и как их решать.
Дисклеймер: По теме я не раз говорил на митапах Webpurple, но структурировать все в текст так и не вышло нормально. Пост — просто изливание кучи мыслей, не структурирован, хотя планировалось нечто большое на несколько иную тему, в черновиках лежал больше, чем полгода, но, как говорил Тим, надо признаться, что черновики не допишутся и публиковать как есть, вот публикую. Ниже все исключительно ИМХО.
Повествование я начну как обычно — с небольшого отступления в прошлое. Когда я начинал работать как разработчик, я никогда не был против задач не для разработчика (как сейчас считается): сервер настроить, сконфигурировать прокси, сборщик из пачки sh-скриптов подкрутить, еще что-то. Да, эти задачи я решал постольку-поскольку, не использовал всякие крутые штуки и инструменты, до поры до времени ни про вагрант, ни про ансибл не слышал, но задачи решал и мне в целом нравилось.
Что касается специализаций и развитий навыков, я приверженец T-shape подхода: в основном я фронтендер, но и в DevOps с бэкендом могу. Вот благодаря этому пересечению с девопсом я гордо могу назвать себя FrontOps’ом.
Появление FrontOps
Вторая часть слова — Ops. Когда говорят про Ops, вспоминается DevOps. Несколько обидно, что почему-то в DevOps не всегда включают FrontEnd, шутка про формошлепов на это есть свои причины, но начнем с того, что такое DevOps.
DevOps — методология взаимодействия специалистов по разработке (Dev) со специалистами по информационно-технологическому обслуживанию (Ops) и интеграцию их рабочих процессов друг в друга для обеспечения качества продукта.
Wikipeadia — DevOps
В диалогах я слышал что-то вроде: «Какие еще оперейшены во фронтоне?! Че там оперировать, статика же?», — наверно, поэтому как-то это все в отдельное направление и выделилось местами. Изначально, девопс — это больше про бэкенд и все, что около него, как-то так сложилось исторически, во всяком случая я чаще сталкивался с таким, что в рамках девопс-процессов о фронтенде никто особо не думал, и это как-то само должно было решаться. Ведь что нужно бэкенду? Кластер серверов, лоадбалансинг, умный деплоймент с нулевым даунтаймом, скейлинг и много всего сложного и интересного. А что на фронтенде обычно было? Отдать статику (часто через тот же бэкенд) и все, но сейчас времена другие.
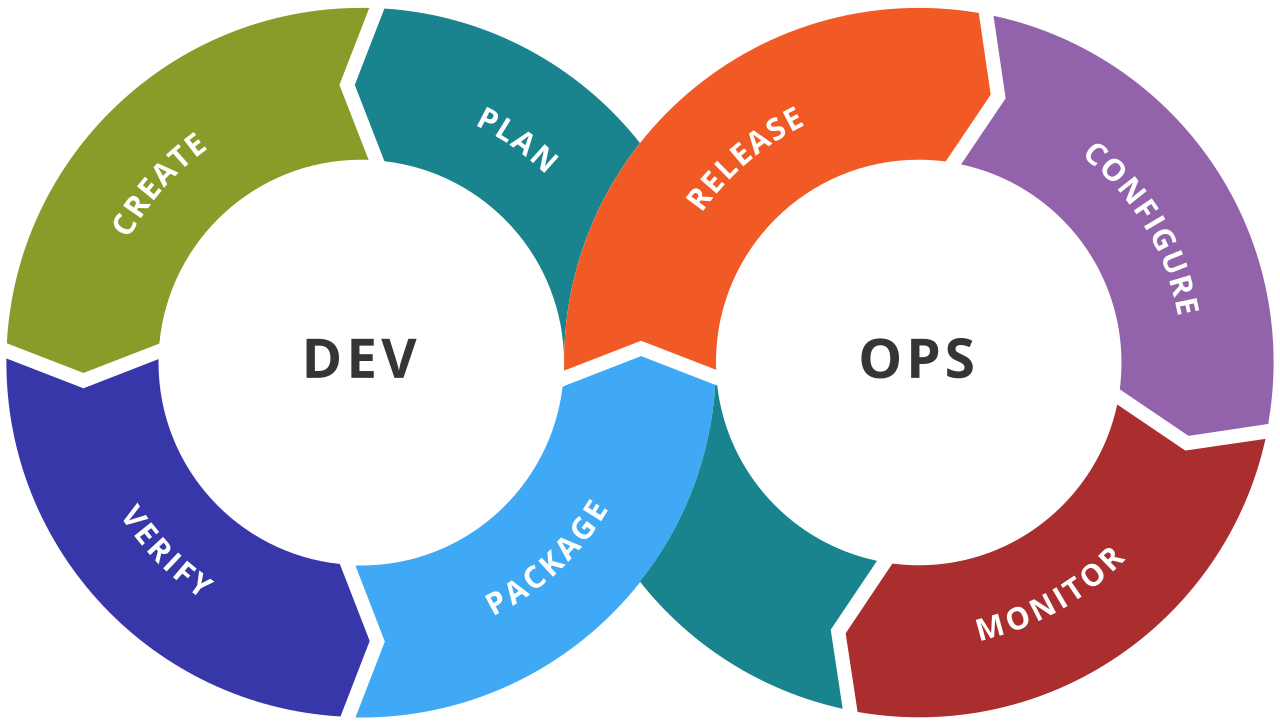
В итоге, отпочковался фронтопс. Фронтопс — ничто иное, как перенос девопс-практик на фронтенд. Те же практики, те же решаемые задачи, просто с некоторой спецификой что ли. Девопс (и фронтопс, выходит, тоже) подразумевает работу по некоторому циклу из определенных шагов с использованием определенных техник и инструментов.
Проблема FrontEnd ~ Ops
После того, как код написали, с ним еще много интересного происходит до того, как он начнет решать задачи пользователя и бизнеса, да и в процессе выполнения этих задач интересное не заканчивается. На бэкенде, разработчики в большинстве своем представляют, что с кодом происходит, после того, как он скомпилировался, так как по-другому там жить довольно сложно, надо все-таки понимать, кто там jar’ник запустил и какие и куда пакеты летают, бэкендерам даже надо понимать, что такое TCP, например (!!!).
В мире фронтенда ситуация несколько иная. На один мой комментарий в ревью «этот код не соберется вот по этой причине, вот линк, почитай, интересная штука» мне отвечали «я простой разработчик, это меня не касается» (утрирую, но примерно так было). WTF? В тот момент я понял, что что-то не так.
Откуда растут ноги этой проблемы? Из времен, когда разработка фронтенда заключалась в запуске сервера статики (и то не всегда) и изменения файликов, которые тут же отображаются в браузере, а деплой заключался в том, чтобы отдать файлики бэкендерам, а они там в jsp перегонят и сами разберутся, или загрузить файлики через FTP на другой сервер. Просто, круто, DX на высоте, код написал и все.
Мир меняется, требования растут, технологии усложняются. Сначала начали гонять файлы через различные инструменты, которые код бандлят и транспилируют, потом этапы стали сложнее и дольше, а файлов стало больше, добавились дополнительные этапы, куча библиотек, фреймворки. С одной стороны, сейчас ситуация совсем другая, но с другой — для многих разработчиков все остается так же с небольшим усложнением:
- `git clone` — оп, код у меня;
- `npm install` — ну, зависимости у меня, погнали;
- `npm start` — ммм, *клик-клац-клик*, все, написал;
- `git commit -a && git push` — отлично, таску в резолв.
С точки зрения разработчика ничего особо не поменялось, но появилась какая-то магия, которая где-то там что-то делает. Разработчик не знает, как оно работает внутри и что происходит с кодом после пуша, да даже не после пуша, а после сохранения файлика, кто над этим файликом колдует на его компьютере, во что превращается этот файлик. Рассмотрим выдуманную историю. В один момент было решено переехать из одного облака в другое и допилить пару крупных фич. Для этого надо в зависимоти от инстанса приложения нужно обращаться к различным сервисам, чуть-чуть подпилить сборку проекта, чтобы он собирал все в несколько бандлов и парочку шрифтов подключить.
Вроде бы задача понятна, но для многих разработчиков фронтенда она нерешаема по одной простой причине: они слишком отдалились от инструментов разработки и не успели подстроиться под их изменения, да и думать об этом часто не нужно, и «вообще пусть это девопсы делают, оперейшены все-таки». Но откуда девопс-инженерам знать о том, как код должен собираться вебпаком? А тем более о всяких узких местах, типа хранений шрифтов на том же домене, чтобы лишний dns-запрос не делался?
Много разработчиков на C++ вы знаете, которые не понимают, как линкуются библиотеки и не могут написать make-файл? А фронтендеров таких много, и это часто не проблема фронтендера, да и не проблема это, просто у нас много инструментов, которые легко устанавливаются и все делают сами.
Хорошо, когда инструменты настолько удобны, что легко решают все проблемы за тебя. Плохо, когда ты не представляешь, как они это делают.
Решаем проблемы
Фронтопс — это не только девопс + фронтенд, фронтопс — то, что нужно знать фронтенд разработчику, для того, чтобы быть действительно фронтенд разработчиком, ведь закомиченный код — далеко не результат работы. Нужно понимать, что с кодом происходит, куда он потом помещается и как доходит до пользователя.
Если вы понимаете, что происходит с вашим кодом в вашем проекте, напишите к этому документацию, устройте пару созвонов, где покажете остальным участникам команды, что и как просиходит в процессе сборки, непрерывных интеграций, деплоя.
Если вы не понимаете этого, изучите проект и инструменты, которые в нем используются, почитайте документацию к ним, спросите более опытных тиммейтов, сделайте собственный стартер или пет-проджект, накрутите там крутой CI/CD, оптимальную сборку.
Изучение «оперейшенов» на базовом уровне занимает не так много времени, но это очень ценный и полезный опыт, который положительно скажется на кругозоре и понимании того, как вообще работает проект и какую роль в нем занимает фронтенд.
Инструменты, о которых нужно иметь представление
- Вебпак, бабел, бандлеры, таск-раннеры (Webpack, Babel, npm-scripts, Gulp) — изучите принцип работы сборщиков и компиляторов JavaScript, TypeScript, CSS, поймите разницу между Rollup и Webpack, изучите возможности npm-scripts и Gulp (хоть его и мало кто использует сейчас).
- Форматтеры, линтеры, статические анализаторы (ESlint, Prettier, stylelint, SonarQube) — хватит спорить на ревью о том, где должна стоять запятая, хватит мутировать иммутабельные значения, автоматизируйте проверку этого.
- Git и хуки (Husky, lint-staged, Learn Git) — изучите Git, для вас не должны быть проблемой ребейзы, которые заканчиваются конфликтами, используйте хуки для автоматического запуска проверок.
- Тестирование (Jest, Mocha, Jasmine, Cypress) — изучите инструменты тестирования, способы их использования, виды тестов.
- Дополнительные инструменты для проверок проекта (size-limit, Lighthouse CI) — проверяйте перформанс-метрики вашего проекта прямо на этапе непрерывных интеграций.
- CDN, файлы, сервера и прокси (nginx, S3, CloudFront, Cloudinary) — изучите, как файлы могут храниться и раздаваться.
- Мониторинг (Amplify, Sentry) — настройте мониторинги, отслеживайте, что происходит с кодом при использовании.
- Деплой, сервера, докер (Ansible, Docker, SSH) — изучите подходы к деплою, варианты запуска приложений, научитесь работать с SSH и консолью — это действительно нужный навык.
- CI/CD (GitLab CI) — изучите принципы и подходы к организации CI/CD, сделайте полезный пайплайн для своего проекта или оптимизируйте существующий.